

Что такое классификация и маршрутизация документов с помощью ИИ?
Классификация документов с помощью ИИ — это автоматическое определение типа, категории и содержания документа без участия человека. Маршрутизация — последующая передача этого документа нужному специалисту, отделу или в нужный процесс. Вместе эти две функции составляют ядро интеллектуальной обработки документов (IDP, Intelligent Document Processing).
Разница с ручным подходом принципиальна: сотрудник тратит в среднем более трёх часов в день на поиск, обработку и согласование документов, а ошибки при ручной сортировке достигают 15–20%. ИИ-системы справляются с той же задачей за секунды и с точностью от 92 до 99%, в зависимости от качества обучающих данных и архитектуры модели.
Технология стала стратегической необходимостью: 65% организаций ускоряют проекты по внедрению ИИ для обработки документов, подчёркивая критическую роль технологии в повышении производительности и ускорении принятия решений.
Искали что такое автоматическая классификация документов?
Оставьте заявку на бесплатную консультацию и наш специалист расскажет, как ИИ экономит часы работы вашей команды каждый день.
Какие технологии лежат в основе интеллектуальной обработки документов?
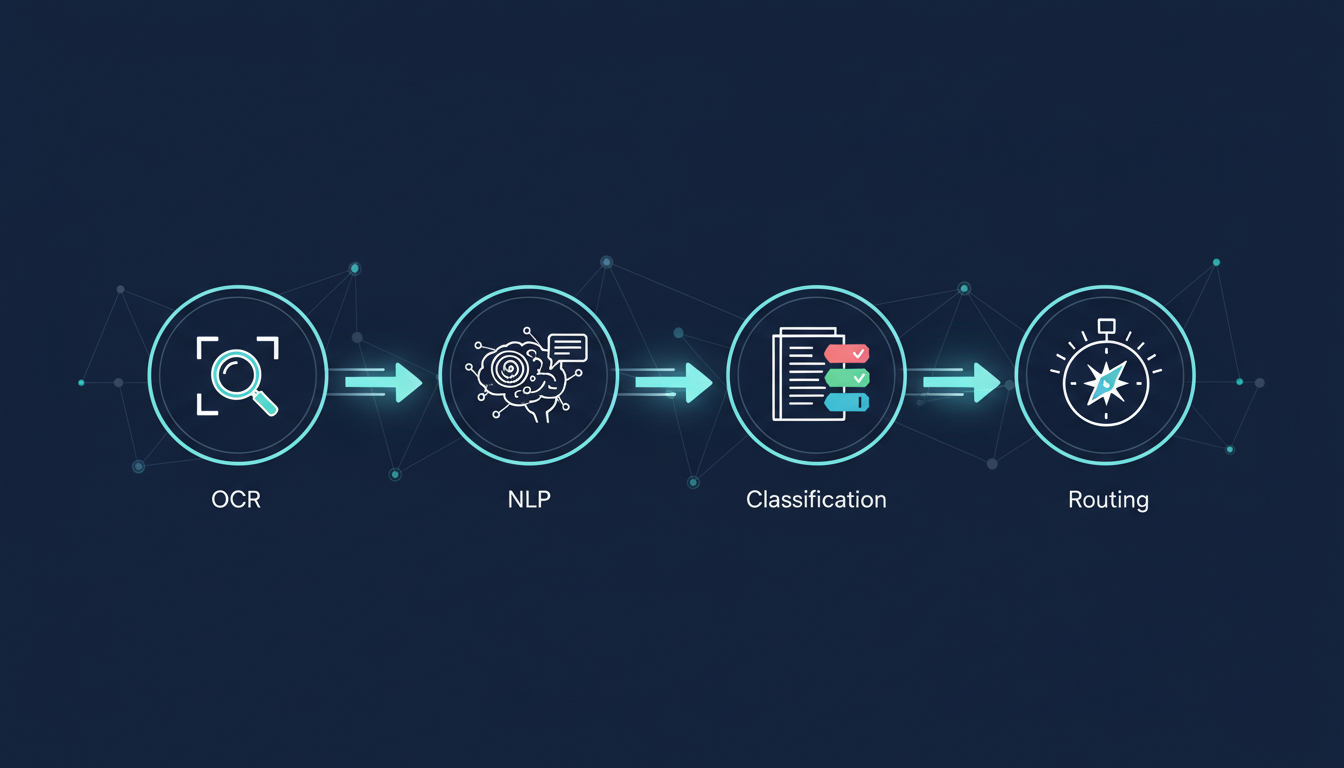
Современные ИИ-системы классификации и маршрутизации строятся на стеке из нескольких взаимодополняющих технологий. Каждая из них решает свою задачу в общем пайплайне.
IDP использует искусственный интеллект (ИИ), машинное обучение (МО), обработку естественного языка (NLP) и оптическое распознавание символов (OCR) для извлечения, классификации и обработки данных из структурированных и неструктурированных документов.
OCR и ICR — первый слой
OCR (Optical Character Recognition) преобразует сканы и изображения в машиночитаемый текст. Следующий уровень — ICR (Intelligent Character Recognition) — умеет распознавать рукописные символы. Современные OCR-движки, например от Smart Engines, позволяют настраивать распознавание различных типов документов, включая нестандартные формы с печатным и рукописным заполнением более чем на ста языках.
NLP — понимание смысла
NLP позволяет искусственному интеллекту «понимать» естественный язык — интерпретировать текст так, как это делает человек. Эта технология используется для классификации документов, извлечения данных, поиска информации по контексту и саммаризации текста.
Трансформеры и LLM — понимание контекста
С появлением трансформерных архитектур (BERT, GPT, LLaMA и их отраслевых версий) точность классификации резко возросла. Системы, использующие трансформерные модели и обученные на доменных данных ML, способны обрабатывать сложные документы, с которыми традиционные правилоориентированные системы не справляются.
Агентные архитектуры — следующий уровень
Агентная обработка документов не просто извлекает данные — она читает контекст, сопоставляет связанные документы, отмечает аномалии и маршрутизирует решения с уровнем суждения, который правилоориентированные системы принципиально не способны воспроизвести.
По данным отчёта Gartner, 67% корпоративных инициатив по обработке документов сегодня рассматривают агентные подходы вместо традиционных стеков OCR + правила.
Как работает пайплайн классификации документов на практике?
Процесс классификации документа с помощью ИИ — это последовательность связанных шагов, каждый из которых можно автоматизировать.
- Захват документа. Система принимает документ из любого источника: электронная почта, мессенджер, сканер, загрузка через API, веб-форма.
- Предобработка. Выравнивание изображения, удаление шума, нормализация формата. На этом этапе ИИ также определяет наличие печатей, подписей, QR-кодов и штрихкодов.
- Распознавание текста (OCR/ICR). Конвертация визуального контента в машиночитаемые данные.
- Извлечение сущностей (NER). Модель выделяет ключевые реквизиты: контрагент, дата, сумма, номер договора, ИНН.
- Классификация. Модель машинного обучения или LLM определяет тип документа (счёт-фактура, договор, акт, рекламация, заявление и т.д.) и его приоритет.
- Валидация. Система сверяет извлечённые данные с эталонными значениями из ERP, CRM или справочников.
- Маршрутизация. На основе классификации документ направляется в нужный отдел, конкретному сотруднику или запускает автоматический workflow.
- Аудит и логирование. Каждое действие фиксируется для обеспечения прозрачности и соответствия требованиям.
Важно понимать, что на автоматизацию с помощью искусственного интеллекта уходит время настройки, но после обучения модели весь цикл от приёма документа до его попадания к нужному исполнителю занимает от 5 до 30 секунд.
Хотите узнать как маршрутизация документов усилит Ваш бизнес?
Покажем на примере вашей индустрии, насколько быстрее и дешевле становится обработка документов с ИИ-решением.
Какие типы документов можно классифицировать автоматически?
ИИ-системы способны работать с широким спектром документов — как структурированных, так и произвольной формы.
| Тип документа | Пример | Типичная сложность классификации |
|---|---|---|
| Финансовые | Счёт-фактура, УПД, ТОРГ-12, накладная | Низкая — высокая структурированность |
| Договорные | Договор поставки, NDA, агентский договор | Средняя — разнообразие шаблонов |
| Кадровые | Заявление, приказ, трудовой договор | Средняя — смешанный формат |
| Юридические | Исковое заявление, судебное решение, жалоба | Высокая — сложный юридический язык |
| Клиентские обращения | Email, сообщение в чате, форма заявки | Высокая — свободная форма |
| Медицинские | Направление, выписка, история болезни | Высокая — специализированный словарь |
| Госуслуги | Заявления, лицензии, разрешения | Средняя — стандартизированные формы |
| Логистические | ТТН, CMR, таможенная декларация | Средняя — международные стандарты |
Неструктурированные документы — электронные письма, контракты, отчёты и отсканированные формы — занимают доминирующее положение в корпоративном документообороте. Именно с ними ИИ справляется лучше всего по сравнению с традиционными инструментами.
Как настроить маршрутизацию документов с помощью ИИ: пошаговая инструкция
Маршрутизация — это практическое применение результатов классификации. Вот как выстроить систему с нуля.
- Аудит текущего документооборота. Зафиксируйте все входящие потоки документов, их типы, объём и существующие правила распределения. Без этого шага невозможно обучить модель.
- Определение бизнес-правил. Задайте, какой тип документа должен попадать к каким сотрудникам или в какие системы. Например: счёт-фактура → бухгалтерия → 1С; рекламация → отдел качества → CRM.
- Подготовка обучающей выборки. Разметьте исторические документы (минимум 200–500 примеров каждого класса). Качество обучающих данных, на основе которых строится модель машинного обучения, критически важно: чем выше качество данных, тем точнее будет классификация.
- Выбор платформы IDP. Подберите решение под задачи: облачное или on-premise, с поддержкой нужных языков и форматов.
- Обучение и тестирование модели. Запустите пилот на реальных документах. Тестируйте на данных, которые не входили в обучающую выборку.
- Интеграция с корпоративными системами. Платформы IDP позволяют решить проблему переноса данных из документов в 1С, CRM, BPM, ERP и другие корпоративные информационные системы.
- Запуск и мониторинг. Начните с гибридной схемы: сложные случаи отправляются на ручную проверку. Постепенно снижайте долю ручного труда по мере роста точности модели.
- Регулярное дообучение. Необходимо регулярно обновлять и переобучать модели, чтобы они адаптировались к изменениям в документообороте.
Какой эффект даёт внедрение ИИ в документооборот?
Внедрение ИИ в классификацию и маршрутизацию документов даёт измеримый и быстрый результат.
По данным McKinsey, автоматизация документальных процессов позволяет сократить затраты на обработку до 40% и сократить время обработки до 70%.
IDP позволяет сократить время обработки документов на 50% и более. Рутинные задачи, которые раньше занимали часы или дни, теперь выполняются за минуты.
Конкретные кейсы подтверждают эти цифры:
- Логистическая компания сократила время обработки документа с более 7 минут до менее 30 секунд — снижение более чем на 90%.
- Eletrobras сообщила о снижении ручной обработки на 90%, сэкономив более 10 000 рабочих часов.
- Команда кредиторской задолженности, которая раньше проверяла вручную 40% счетов, теперь проверяет только 4%.
Внедрение IDP часто приносит высокий ROI: исследования показывают 30–200% возврата инвестиций в первый год автоматизации, прежде всего за счёт экономии на трудозатратах.
Компании, которые решаются на внедрение искусственного интеллекта в бизнес-процессы, получают измеримый результат уже в первые месяцы — сокращение трудозатрат, рост скорости согласования и снижение числа ошибок одновременно.

Сколько времени ваша команда теряет на ручную сортировку документов?
Давайте посчитаем потери вместе и покажем, как автоматизация окупается за месяцы. Оставьте контакт — свяжемся в течение часа.
Обзор платформ и инструментов для классификации документов
Рынок IDP-решений активно развивается. Объём глобального рынка интеллектуальной обработки документов составил $3,22 млрд, с прогнозом роста до $43,92 млрд к 2034 году.
| Платформа | Ключевые возможности | Целевая аудитория |
|---|---|---|
| UiPath Document Understanding | Классификация, извлечение, валидация, RPA-интеграция | Крупный бизнес, банки |
| ELMA AI | Классификация обращений, маршрутизация по правилам, работа с СЭД | Российские компании |
| Smart Document Engine | On-premise, без GPU, 70+ типов бизнес-документов | Банки, госсектор, страхование |
| Microsoft Azure AI Document Intelligence | Облако, мощные трансформеры, интеграция с M365 | Enterprise, мировые компании |
| Google Document AI | Мультимодальность, высокая точность OCR | Технологические компании |
| Docsumo | Счета, накладные, лёгкая интеграция по API | SMB, стартапы |
| Graip.AI | Агентный подход, предсказательная обработка | Средний и крупный бизнес |
UiPath Document Understanding объединяет роботизированную автоматизацию процессов, ИИ и машинное обучение для извлечения, классификации и валидации данных из различных типов документов. Решение помогает организациям обрабатывать большие объёмы неструктурированных документов с минимальным участием человека.
Для российского рынка особую ценность представляют системы с on-premise развёртыванием без передачи данных, поддерживающие более 70 ключевых бизнес-документов, включая счета-фактуры, накладные, УПД, ТОРГ-12, выписки из ЕГРЮЛ и ЕГРИП.
Классификация обращений: отдельный случай маршрутизации
Отдельного внимания заслуживает маршрутизация входящих клиентских обращений — одна из самых востребованных задач для e-commerce, банков и сервисных компаний.
Модуль ELMA AI анализирует обращения с почты, мессенджеров и соцсетей и перенаправляет их на нужного специалиста или в необходимый департамент. Система классифицирует и маршрутизирует любые входящие обращения по текстовому содержанию, независимо от формата, источников и вложений.
Это критично для маркетплейсов и интернет-магазинов, где ежедневно поступают сотни обращений: возвраты, жалобы, уточнения по заказам, запросы документов. Без ИИ-сортировки каждое из них требует ручного чтения и переадресации. С ИИ — система распознаёт суть обращения, написанного даже в свободной форме, и немедленно отправляет его нужному исполнителю.
Например, в крупной организации, получающей сотни контрактов ежедневно, система автоматически категоризирует их по типу и направляет в нужный отдел — юридический, закупочный или отдел соответствия — без ручного вмешательства.
Как ИИ меняет согласование документов внутри компании?
Классификация и маршрутизация — лишь начало. Следующий шаг — интеллектуальное согласование.
Искусственный интеллект разделяет документ на части, назначает ответственного за конкретный раздел и запускает автоматическую маршрутизацию частей в зависимости от их содержания. Это означает, что сложный договор одновременно отправляется юристу (на правовые условия), финансисту (на стоимостные блоки) и техническому эксперту (на спецификации) — параллельно, а не последовательно.
В процессе утверждения счетов счета ниже определённого порога утверждаются мгновенно, тогда как более крупные суммы помечаются для дополнительной проверки.
Предиктивная составляющая не менее важна: системы с предиктивным анализом процессов прогнозируют задержки в согласованиях и движении документов, что позволяет менеджерам вмешаться до того, как дедлайн будет нарушен.
Чтобы понять, насколько глубоко ИИ проникает в корпоративные процессы, рекомендуем изучить полный обзор применения ИИ в управлении компанией — от планирования до контроля исполнения задач.
Требования к данным: как подготовить компанию к внедрению?
Одна из главных причин провала ИИ-проектов — неготовность данных. По данным отчёта MIT Sloan Management Review, 95% пилотов генеративного ИИ в компаниях не принесли ожидаемой ценности или не вышли на стадию масштабирования.

Во многих случаях организации слишком поздно обнаруживали, что их данные неполны, противоречивы или структурно непригодны для автоматизации. Растущий тренд — акцент на готовности данных как критическом этапе IDP-проектов. Организации всё больше инвестируют время на предварительную оценку качества документов, зрелости процессов и пробелов в управлении.
Чек-лист готовности данных перед внедрением:
- Наличие размеченного архива документов (минимум 500–1000 примеров каждого класса)
- Единые форматы хранения (PDF, DOCX, JPEG — уточнить у вендора)
- Описанные бизнес-правила маршрутизации
- Доступ к API корпоративных систем (1С, SAP, CRM)
- Назначенный владелец процесса со стороны бизнеса
- Политика обработки персональных данных и коммерческой тайны
Важно обеспечить безопасность данных, используя современные методы шифрования и защиты информации.
Регуляторные требования и compliance при работе с ИИ-документооборотом
При внедрении ИИ в обработку документов компании сталкиваются с растущими требованиями регуляторов.
Положения EU AI Act о правоприменении начали распространяться на высокорисковые ИИ-системы. Обработка документов в финансовых услугах, страховании и здравоохранении попадает под критерий высокого риска в большинстве трактовок.
Соответствие требованиям в контексте Document AI включает: полные аудиторские следы по каждому решению об извлечении, объяснимость того, почему документ был классифицирован или маршрутизирован определённым образом, рабочие процессы с участием человека, которые можно продемонстрировать регуляторам, и средства контроля резидентности данных.
Для российских компаний актуальны требования 152-ФЗ о персональных данных, требования ЦБ к банковским системам и отраслевые стандарты. Системы с возможностью on-premise развёртывания позволяют держать все данные внутри корпоративного контура без передачи в облако.
Отдельный аспект — объяснимость решений ИИ. Если система направила договор не в тот отдел, сотрудник должен понимать, почему это произошло, и иметь возможность скорректировать решение. Это требование к explainable AI (XAI) становится де-факто стандартом для enterprise-внедрений.
Тренды и будущее интеллектуальной обработки документов
Наиболее трансформирующий тренд — переход от реактивной к предиктивной автоматизации документов. Традиционный IDP фокусировался на обработке существующих документов (извлечение, классификация, маршрутизация, утверждение) и реагировал только после наступления событий.
Предиктивный интеллект документов может помечать счета, отклоняющиеся от бюджетов, прогнозировать платёжные циклы и предупреждать команды о предстоящих продлениях контрактов или регуляторных изменениях. Политики соответствия могут обновляться проактивно, а не под давлением дедлайнов.
Ключевые тренды, которые определяют отрасль прямо сейчас:
- Мультимодальность. Объединение текста, изображений и голоса в единый пайплайн обработки.
- Отраслевая специализация. Рынок IDP решительно отходит от идеи универсального решения, одинаково хорошо работающего для каждого бизнеса.
- Агентные системы. Один из значимых сдвигов — рост агентных архитектур: вместо предопределённых рабочих процессов новая модель строится вокруг агентов, которые преследуют цели, а не выполняют заранее прописанные шаги.
- Low-code/no-code. Провайдеры IDP всё активнее предлагают возможности с низким или нулевым кодом, позволяя гражданским разработчикам самостоятельно строить процессы захвата и обработки документов.
- Генеративный ИИ. Ожидается, что более 80% предприятий будут использовать API или модели генеративного ИИ, что существенно улучшит различные операции, включая обработку документов.
Понять, как эти технологии встраиваются в более широкую экосистему, поможет полный обзор технологий ИИ для бизнеса — от машинного обучения до мультиагентных систем.
Продавайте с
комиссией 0%
Команда маркетологов бесплатно откроет интернет-магазин на платформе Яндекс KIT и все запустит. От Вас нужен только план продаж.
Отраслевые кейсы применения ИИ в классификации документов
Рассмотрим, как разные отрасли уже получают конкурентное преимущество от внедрения ИИ-классификации.

Банки и финансы. Сектор финансовых услуг доминирует на рынке Document AI: системы используются для обнаружения мошенничества, автоматизации страховых требований, верификации KYC и мониторинга соответствия нормативам. Банк, обрабатывающий тысячи кредитных заявок ежедневно, с помощью ИИ автоматически классифицирует документы заявителя, извлекает необходимые реквизиты и маршрутизирует пакет к нужному кредитному аналитику — за 20–30 секунд вместо 15–20 минут.
E-commerce и логистика. Обработка накладных, ТТН, актов приёмки — типичная задача для онлайн-ритейлеров. В финансовом секторе IDP-гиперавтоматизация существенно сокращает время обработки кредитных заявок, автоматически верифицируя документы и маршрутизируя согласования. Аналогичная логика применима и к логистическим документам.
Здравоохранение. Направления и лабораторные формы автоматически классифицируются и направляются в правильный отдел. Это сокращает время ожидания пациентов и снижает нагрузку на регистратуру.
Государственный сектор. Обработка заявлений граждан, лицензионных запросов, обращений — сферы, где ИИ позволяет обслуживать больше запросов без роста штата. Российские решения, такие как Smart Engines, специально ориентированы на банки, страховые компании, госучреждения и интеграторов.
Юридические компании. Ежедневная обработка договоров, судебных актов, переписки — объём настолько велик, что ручная сортировка становится неприемлемой. ИИ позволяет не просто классифицировать документ, но и выделять ключевые условия, риск-факторы и сроки. С тем, как ИИ меняет сферу судопроизводства и юридической работы, стоит ознакомиться отдельно.
Как избежать типичных ошибок при внедрении ИИ-классификации?
Опыт сотен внедрений позволяет выделить типичные ловушки, которых следует избегать.
Ошибка 1: Запуск без аудита данных. Компании начинают проект без понимания объёма и качества своих документов. Итог — модель обучена на «мусоре» и классифицирует с точностью 60–70%, что хуже ожидаемого.
Ошибка 2: Попытка автоматизировать всё сразу. Не каждая задача выигрывает от недетерминированных рассуждений. Простые шаги извлечения или классификации по-прежнему лучше обслуживаются традиционной автоматизацией. Начинайте с самых повторяющихся и однородных классов документов.
Ошибка 3: Отсутствие human-in-the-loop. Полное исключение человека из процесса недопустимо на старте. Нужен механизм, когда модель «не уверена» (низкий confidence score) — документ уходит на ручную проверку.
Ошибка 4: Игнорирование интеграции. Классифицировать документы недостаточно. Если результат не попадает автоматически в 1С, ERP или CRM — ценность системы резко снижается.
Ошибка 5: Одноразовое обучение. Документооборот компании меняется: появляются новые типы документов, контрагенты присылают обновлённые шаблоны. Без регулярного дообучения точность модели деградирует.
Для тех, кто хочет глубже разобраться в потенциальных рисках, есть подробный материал о рисках внедрения искусственного интеллекта — от технических до организационных.
Сколько стоит внедрение ИИ для классификации документов?
Стоимость зависит от масштаба, выбранного подхода и необходимого уровня кастомизации.
| Подход | Стоимость | Сроки внедрения | Для кого |
|---|---|---|---|
| Готовое SaaS-решение | от 15 000 ₽/мес. | 2–4 недели | SMB, стартапы |
| Облачное enterprise-решение | от 150 000 ₽/мес. | 1–3 месяца | Средний и крупный бизнес |
| On-premise лицензия | от 1 500 000 ₽ разово | 3–6 месяцев | Банки, госсектор |
| Кастомная разработка | от 3 000 000 ₽ | 6–12 месяцев | Уникальные бизнес-процессы |
Исследования показывают ROI 30–200% в первый год автоматизации, преимущественно за счёт экономии на трудозатратах. Компании окупают инвестиции в IDP в размере одно-трёхкратного возврата уже в первый год.
При оценке бюджета учитывайте не только стоимость лицензии, но и затраты на разметку данных (если нет готовой выборки), интеграцию с корпоративными системами, обучение сотрудников и поддержку модели. Для малого и среднего бизнеса существуют специализированные решения, не требующие больших первоначальных вложений.
Компании, которые уже сейчас обращаются за внедрением ИИ-решений для автоматизации документооборота, получают конкурентное преимущество, которое с каждым месяцем становится всё сложнее наверстать.
Часто задаваемые вопросы
Что такое IDP и чем он отличается от обычного OCR?
IDP (Intelligent Document Processing) — это комплексная технология, объединяющая OCR, NLP, машинное обучение и бизнес-логику. Обычный OCR только переводит изображение в текст, тогда как IDP понимает смысл документа, определяет его тип, извлекает нужные реквизиты и автоматически маршрутизирует в нужный процесс. Разница — как между сканером и квалифицированным делопроизводителем.
С каких документов лучше всего начинать автоматизацию классификации?
Начинайте с наиболее однородных и массовых типов: счетов-фактур, накладных, стандартных заявлений. Эти документы имеют предсказуемую структуру, что позволяет быстро обучить модель с высокой точностью (95%+) и получить ROI за 3–6 месяцев.
Какая точность классификации достижима на практике?
Современные ИИ-системы достигают 92–99% точности на хорошо структурированных документах при наличии качественной обучающей выборки. Для документов в свободной форме (обращения клиентов, письма) точность составляет 85–95% и растёт с накоплением данных.
Нужно ли программировать для настройки ИИ-классификации?
Нет, современные платформы предоставляют low-code и no-code интерфейсы для настройки правил классификации и маршрутизации. Технический специалист потребуется только для интеграции с корпоративными системами (API-подключение к 1С, CRM, ERP).
Как ИИ-классификация работает с русскоязычными документами?
Российские решения (Smart Document Engine, ELMA AI, Content AI) специально оптимизированы для русскоязычных документов, включая специфику российских реквизитов (ИНН, ОГРН, КПП), форм первичной документации (ТОРГ-12, УПД, счёт-фактура) и шаблонов государственных органов. Международные платформы (Azure AI, Google Document AI) также поддерживают русский язык, но могут требовать дополнительной донастройки.
Безопасно ли передавать документы на обработку в облачные ИИ-системы?
Вопрос зависит от типа документов и политики компании. Для документов, содержащих персональные данные или коммерческую тайну, рекомендуется on-premise развёртывание или гибридная схема. Большинство enterprise-платформ предлагают оба варианта с шифрованием в транзите и при хранении.
Сколько времени занимает внедрение ИИ-классификации документов?
Пилот на одном типе документов запускается за 2–4 недели. Полноценная система с поддержкой 10–20 типов документов и интеграцией с корпоративными системами требует 2–4 месяца. Корпоративные проекты со сложной инфраструктурой — от 4 до 12 месяцев.